

Pixivスクレイピングの背景: PixivのAPI制限とWebスクレイピングの重要性
最近、絵師である友人から特定のPixivの人気度をスクレイピングしたいとの相談を受けました。
Pixivは、数多くのイラストが共有される人気のプラットフォームで、毎日数千の新しい作品がアップロードされます。これらの作品の「いいね」数やブックマーク数などの情報は、作品の人気やトレンドを理解する上で貴重なデータとなります。
今回私はせっかくの機会ですしChatGPT にもスクレイピングプログラㇺを書かせてみます。
PixivのAPI制限
かつてはPixivが提供していた公式APIを使用することで、これらのデータを取得することが可能でした。しかし、現在は一部の機能が制限されたり、利用が困難になることがあります。このため、今回はWebスクレイピングでそれらの情報を集めてきます。
Webスクレイピングの必要性
Webスクレイピングは、ウェブサイトから必要な情報を自動的に取得する技術です。API制限がある場合や、特定のデータにアクセスする公式の方法がない場合に、非常に有用です。
特に、絵師やマーケターにとって、Pixivの人気度やトレンドを把握することは、多くの人に見てもらうためには不可欠でしょう。Pythonを使用したWebスクレイピングは、このような情報を効率的に収集するための強力なツールとなります。
この記事では、PythonとChatGPTを使用してPixivからのデータスクレイピングを行う方法を詳しく解説します。これにより、Pixivの人気度を自動的に追跡し、分析することが可能になります。
Pythonでpixivをスクレイピング
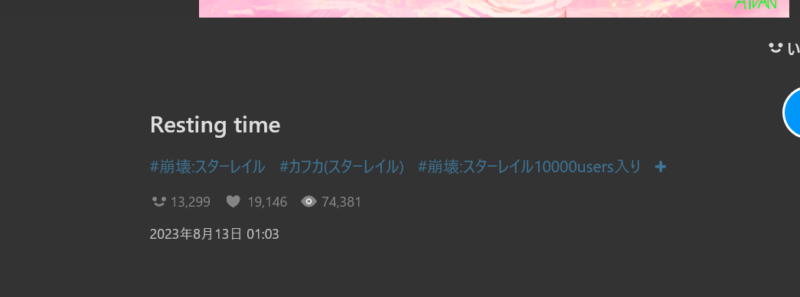
今回のゴールは与えられたURLからpixivページ内の「いいね」とブックマーク数を取得することです。
Webスクレイピングは、ウェブページから情報を取得するための技術です。Pythonは、その簡潔さと強力なライブラリにより、スクレイピングのための最適な言語の一つとなっています。ここでは、Pythonを使用したスクレイピングの基本的な手法と、特にPixivからのデータ取得に必要な手順について解説します。
今回作成したコード
import requests
from bs4 import BeautifulSoup
import json
#URL末の数字をセット(スクレイピングして得られる辞書のkeyとして使うため)
ILLUST_ID = 110775981
def getBookLike(id):
URL = "https://www.pixiv.net/artworks/" + str(id)
r=requests.get(URL)
soup = BeautifulSoup(r.content, "html.parser")
#contentにはmetaタグに入っていた辞書を格納(この段階ではstr型)
content = soup.find_all("meta", id="meta-preload-data")[0].get("content")
#ブックマーク(json.loadsでstr->辞書型、辞書のkeyは.keys()関数を使って根気で探す)
bookmark = json.loads(content)["illust"][str(id)]["bookmarkCount"]
#いいね数
like = json.loads(content)["illust"][str(id)]["likeCount"]
return[bookmark,like]
def main():
booklike = getBookLike(ILLUST_ID)
print("ブックマーク:%s\nいいね:%s" %(booklike[0],booklike[1]))
if __name__ == "__main__":
main()ブックマーク:18242
いいね:12719
requests: ウェブページのデータ取得
requests は、PythonでHTTPリクエストを簡単に行うためのライブラリです。これを使用して、PixivのページからHTMLデータを取得します。
import requests
URL = "https://www.pixiv.net/artworks/" + str(id)
r=requests.get(URL)BeautifulSoup: HTMLデータの解析
BeautifulSoup は、HTMLやXMLの解析を容易にするPythonのライブラリです。requests で取得したHTMLデータを解析し、必要な情報を抽出します。
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, "html.parser")
#contentにはmetaタグに入っていた辞書を格納(この段階ではstr型)
content = soup.find_all("meta", id="meta-preload-data")[0].get("content")
#ブックマーク(json.loadsでstr->辞書型、辞書のkeyは.keys()関数を使って根気で探す)
bookmark = json.loads(content)["illust"][str(id)]["bookmarkCount"]
#いいね数
like = json.loads(content)["illust"][str(id)]["likeCount"]今回はHTML内に要素数のとても多い辞書を見つけましたので.keys()関数を使って根気で解析していきました。
ChatGPTに書かせてみた
ここからはChatGPTにスクレイピングのプログラムを書かせてみます。
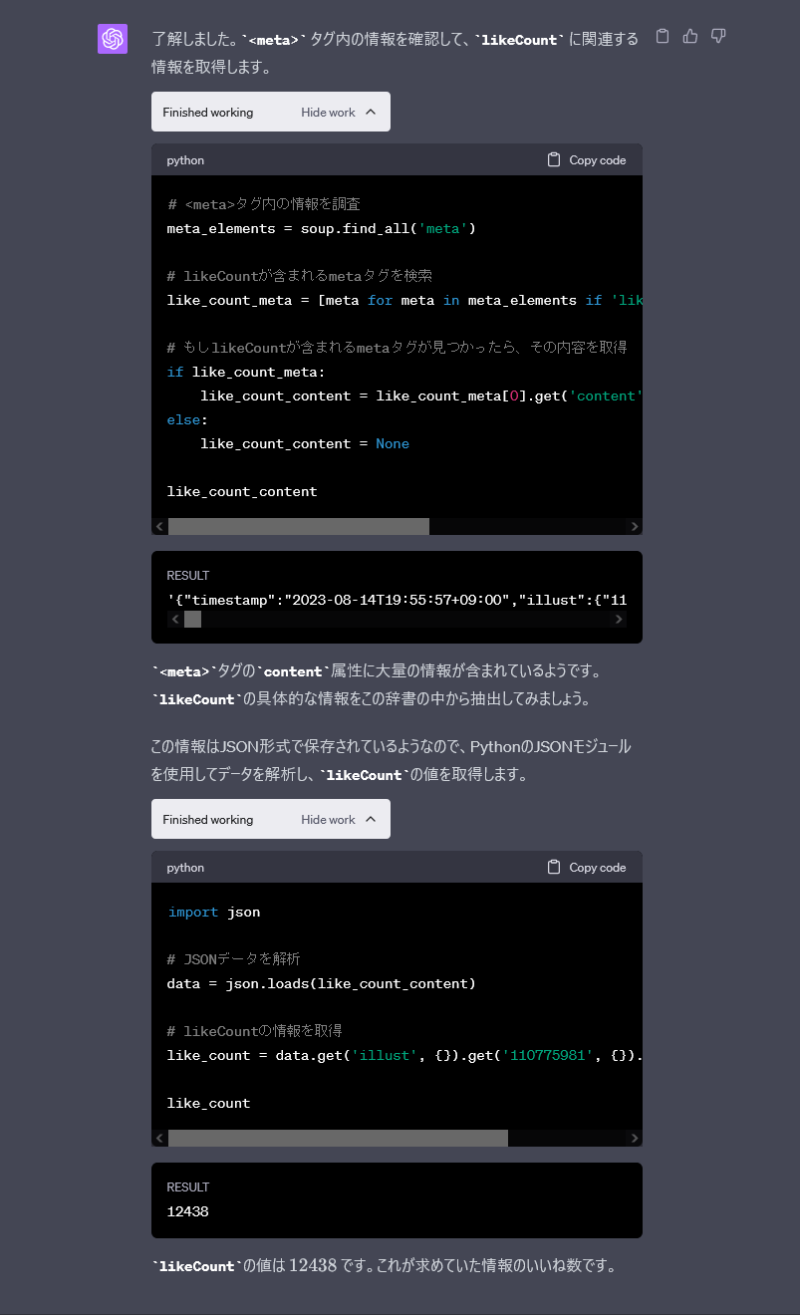
すごい。ものの数十秒で書き上げてしまいました。
ChatGPTに出力のhtmlファイルを渡すことで、URLにアクセスできないという壁を乗り越えてスクレイピングのコードを書いてくれるのです。
これらのコードをまとめてもらったのが以下です。
def extract_like_count_from_html(file_path):
# HTMLファイルを開く
with open(file_path, "r", encoding="utf-8") as file:
content = file.read()
# BeautifulSoupでHTMLを解析
soup = BeautifulSoup(content, 'html.parser')
# likeCountが含まれるmetaタグを検索
like_count_meta = [meta for meta in soup.find_all('meta') if 'likeCount' in meta.get('content', '')]
# もしlikeCountが含まれるmetaタグが見つかったら、その内容を取得
if like_count_meta:
like_count_content = like_count_meta[0].get('content')
else:
return None
# JSONデータを解析
data = json.loads(like_count_content)
# likeCountの情報を取得
return data.get('illust', {}).get('110775981', {}).get('likeCount')
このままではhtmlファイルを参照するので多少の書き換えは必要ですが、あれだけ複雑だった辞書からほしい情報を瞬時に見つけてくる点はやはりさすがでした。
まとめ: PythonとChatGPTの力でPixivのスクレイピングを最適化

このガイドでは、Pixivの「いいね」やブックマーク数を自動で取得するためのPythonスクレイピングの基本を解説しました。特に、ChatGPTの助けを借りることで、多くの課題を効果的に解決し、スクレイピングの効率を上げることができそうです。
Webスクレイピングは、データ収集のための非常に強力なツールですが、それに伴うルールや課題も多いですので実際に行う際にそのサイトの確認をしてから行いましょう。
今後もPixivや他のウェブサイトのデータ収集の際に、このブログが参考として役立つことを願っています。






