

こんにちは、大学院で情報セキュリティを勉強しています。りょうです。
皆さんいかがお過ごしでしょうか。
前回の記事ではダークウェブについて少しだけまとめてみました。
今回の記事の前提などを書きましたので、もし暇だよという方がいらっしゃれば読んでいただけると幸いです。

ダークウェブにアクセスするためにはTorなどを利用して身元を隠す必要がありますが、その特性から自分のIPアドレスを隠せるため多く犯罪の温床になったりしています。
特に一般的なwebサイトへのサイバー攻撃の際もTor通信を使って足が付かない状態で行われるものが多い現状です。
そのため、一般的なwebサイトを作る際にはTorからの通信は拒否するべきです。
今回はその対策方法を考えながら、最終的には機械学習を扱ってTor通信を経ているパケットを判定します。
WEBアプリを作るときはTorからの通信は拒否した方が良い

もし何かwebアプリを作ったとして、そこにTor経由でアクセスしてくる人はおそらく何か良くないことをしようとしている人でしょう。
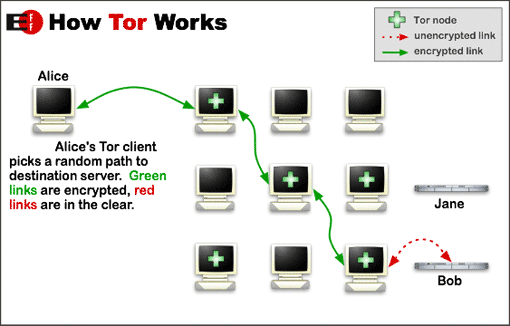
これがTor通信のイメージなのですが、どうにかしてサーバをいくつも経てIPアドレスを隠した通信は拒否したいものです。
世の中の動きとしても、Tor通信はブロックするべきだということになっています。
従来の対策方法

現在知られているTor通信を遮断する方法なのですが、Torのノード情報をブラックリストとしてファイアウォールに登録しておくという方法があります。
Torのノード情報は以下のサイトでまとめてくれていたのでそちらを参考にするとよいでしょう。

Torにつないだ後にVPNを経由すればいいのではないか?
しかしTorのノード情報をブラックリストに登録してもブロックしきれない場合があります。
それは、Tor通信の先にVPNやプロキシサーバを設置した通信の際です。
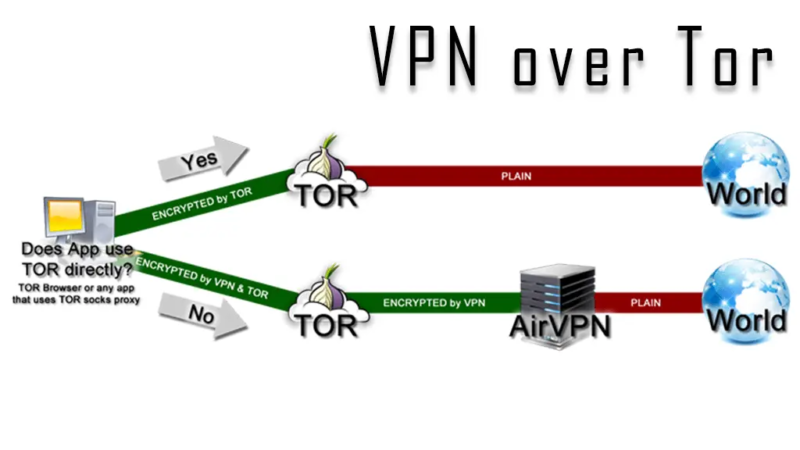
上のイラストのように、ブラックリストに登録されていないサーバを経ての通信は検知することができません。
そこで、IPアドレス以外の情報を使ってなんとかTor通信かどうかを判定したいものです。
機械学習を使ってみよう
前の記事で機械学習を使用して競馬をやってみました。

その時に学んだ機械学習の力を今回も借りたいと思います。
今回の目標
今回の目標は、
- Tor通信を経て任意のIPアドレスからアクセスしてくる通信を見分けたい
- TorのノードからのアクセスではないのでIPアドレスの情報は使えない
- パケットの時間やバイト数などで何とか見分けられないだろうか?
という感じです。
Tor通信のデータセットについて
今回のデータセットは、カナダにあるニューブランズウィック大学が公開しているものを使用します。
名前などの情報を入力したら無料でダウンロードできました。

中身はこんな感じです

各行には、パケットフローに関するIPアドレス、時間、データ量、それがTor通信かどうかなどの情報が記載されています。
目的変数について
今回の目的変数はその通信フローがTor通信かそうではないかの判定とします。
説明変数について
今回の説明変数には以下のようなものが含まれます。

ダウンロードしてきたデータセットのIPアドレスとポート番号以外の情報を使用しました。
機械学習を実装
機械学習の実装にはPython機械学習でおなじみsklearnを使用します。
今回実験するモデルは、
- ランダムフォレスト
- ロジスティック回帰
- k-近傍法
の3種類です。それぞれのモデルの特徴なんかはちゃちゃっと調べてみてください。
さて、実際に実装したソースコードを紹介します。
まずは必要なライブラリをインポートしてきます。
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score次にcsvファイルを読み込んで配列に入れます。
data=[]
var_path = "SelectedFeatures-10s-TOR-NonTOR.csv"
data = pd.read_csv(var_path)
data[data == np.inf] = np.NaN #infをNaNにしたうえでNaNを消す
data = data.dropna(how='any')5、6行目ではデータセットの中のNaN(非数値)とinf(無限数)を除去しています。
今回は代替のデータを入れる作業をめんどくさがったため、一つでもNaNやinfのような欠損値がある行は削除しています。
この処理をしなかったらsklearnを使用した際に
ValueError: Input contains NaN, infinity or a value too large for dtype('float32')といったエラーが出てきてしまいます。
機械学習を扱うときの欠損値の処理は誰しも一度は悩みますよね。
次に、先ほど紹介した目的変数と説明変数のリストを作成します。
#目的変数
y = data['label'].replace({'nonTOR': 0, 'TOR': 1})
#説明変数
useCols = [' Protocol', ' Flow Duration', ' Flow Bytes/s', ' Flow Packets/s', ' Flow IAT Mean', 'Fwd IAT Mean', 'Bwd IAT Mean', 'Active Mean', 'Idle Mean']
X = data[useCols]ランダムフォレストで実行
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0, test_size=0.2)
clf = RandomForestClassifier(n_estimators=1000, random_state=1)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print('Accuracy score: ' + str(accuracy_score(y_test, y_pred)))
print('Precision score: ' + str(precision_score(y_test, y_pred)))
print('Recall score: ' + str(recall_score(y_test, y_pred)))
print(confusion_matrix(y_test, y_pred, labels=[1, 0]))結果は以下でした。
Accuracy score: 0.9831932773109243 Precision score: 0.9338640538885487 Recall score: 0.9270516717325228 [[ 1525 120] [ 108 11813]]
ロジスティク回帰で実行
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0, test_size=0.2)
clf = LogisticRegression(random_state=0)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print('Accuracy score: ' + str(accuracy_score(y_test, y_pred)))
print('Precision score: ' + str(precision_score(y_test, y_pred)))
print('Recall score: ' + str(recall_score(y_test, y_pred)))結果は以下でした。
Accuracy score: 0.8947368421052632 Precision score: 0.5541147132169576 Recall score: 0.6753799392097265 [[ 1111 534] [ 894 11027]]
k-近傍法で実行
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0, test_size=0.2)
clf = KNeighborsClassifier(n_neighbors=5)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print('Accuracy score: ' + str(accuracy_score(y_test, y_pred)))
print('Precision score: ' + str(precision_score(y_test, y_pred)))
print('Recall score: ' + str(recall_score(y_test, y_pred)))
print(confusion_matrix(y_test, y_pred, labels=[1, 0]))結果は以下でした。
Accuracy score: 0.9534129441250184 Precision score: 0.8392498325519089 Recall score: 0.7617021276595745 [[ 1253 392] [ 240 11681]]
割といい結果がでたのでは?
おいにゃにゃにゃにゃ🐈
猫が通りました。
ここでこれまでの結果をまとめてみます。
| モデル\指標 | 精度(Accuracy) | 適合率(Precision) | 再現率(Recall) |
| ランダムフォレスト | 98.31% | 93.38% | 92.70% |
| ロジスティク回帰 | 89.47% | 55.41% | 67.53% |
| k-近傍法 | 95.34% | 83.92% | 76.17% |
ランダムフォレストが最も正解率が高い結果となりました。
ランダムフォレストのテスト結果も見てみましょう。
| 予想:Tor | 予想:Torじゃない | |
| 実際:Tor | 1525 | 120 |
| 実際:Torじゃない | 108 | 11813 |
赤字のところが正解した数です。そこそこいい結果が出たんじゃないじゃないでしょうか。
しかしこのままでは108件の正常な通信を遮断して、120件のTor通信を通してしまします。
ほかの手法を組み合わせることで工夫できないでしょうかね。
一応、ソースコード全体を記載しておきます。
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score
data=[]
var_path = "SelectedFeatures-10s-TOR-NonTOR.csv"
data = pd.read_csv(var_path)
data[data == np.inf] = np.NaN #infをNaNにしたうえでNaNを消す
data = data.dropna(how='any')
#目的変数
y = data['label'].replace({'nonTOR': 0, 'TOR': 1})
#説明変数
useCols = [' Protocol', ' Flow Duration', ' Flow Bytes/s', ' Flow Packets/s', ' Flow IAT Mean', 'Fwd IAT Mean', 'Bwd IAT Mean', 'Active Mean', 'Idle Mean']
X = data[useCols]
#学習データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0, test_size=0.2)
#ランダムフォレスト
clf = RandomForestClassifier(n_estimators=1000, random_state=1)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print('Accuracy score: ' + str(accuracy_score(y_test, y_pred)))
print('Precision score: ' + str(precision_score(y_test, y_pred)))
print('Recall score: ' + str(recall_score(y_test, y_pred)))
print(confusion_matrix(y_test, y_pred, labels=[1, 0]))
#ロジスティク回帰
clf = LogisticRegression(random_state=0)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print('Accuracy score: ' + str(accuracy_score(y_test, y_pred)))
print('Precision score: ' + str(precision_score(y_test, y_pred)))
print('Recall score: ' + str(recall_score(y_test, y_pred)))
#k-近傍法
clf = KNeighborsClassifier(n_neighbors=5)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print('Accuracy score: ' + str(accuracy_score(y_test, y_pred)))
print('Precision score: ' + str(precision_score(y_test, y_pred)))
print('Recall score: ' + str(recall_score(y_test, y_pred)))
print(confusion_matrix(y_test, y_pred, labels=[1, 0]))まとめ
今回は3種類の機械学習アルゴリズムを使用してTorノードを経た通信の判定を行いました。
特にランダムフォレストでは98.31%という正解率を出しました。

やりました。
今後はほかの判定手法との組み合わせなど、工夫を施してみたいと思います。
それではまた。






