

こんにちは、限界大学生のりょうです。

大学院生はお金がない!!!!
常に金欠と隣り合わせの僕らはもう一発逆転するしかありません。
こうなったら競馬で巨万の富を得よう
しかし競馬知識に乏しい僕が自分で予想してもJRAの養分になるだけです。
そこで、今回は勉強もかねてPythonの機械学習を使って絶対に来る馬を予想してやりたいと思います。
機械学習に関する知識はほぼゼロで授業もぎりぎりで単位をもらったので、今回をきっかけに少し詳しくなれればと思っています!
ちなみに、今回参考にした本はこちらです。

競馬AIを作るための手順
上の本には機械学習を実装する手順は、
- ゴールを決める
- データを持ってくる
- データの形を整える
- データを学習させる
- モデル(競馬AI)を評価する
- 精度がよかったら活用する
と書いてありました。
今回の競馬AIのゴールは、その馬が3着以内に入るのかを予想することに設定します。
それでは、データを持ってきましょう!
過去の競馬データを持ってくる
「競馬データ csv」と検索したのですが、どうやら公式に月額2000円ほど払わないとダウンロードできない仕様になっていました。
しかし、僕ら大学院生はその金欠っぷりから今日ももやしで空腹をしのいでいます。
どのみち競馬で大稼ぎするのですが、ここは慎重にその2000円も節約していきます。
他の方法がないかと検索したところ、ある選択肢が浮かんできました。
スクレイピングという選択肢
webには大量のテキスト情報が公開されています。
例えば今回のような大量のデータが必要な時にネットの海から勝手にそれらのデータを持ってきてくれる人がいたら惚れてしまうことでしょう。
実はそのような技術が開発されており、スクレイピングと言ったりします。
今回はPythonで実装するのでBeautiful Soupというパッケージ(Pythonで使える拡張パックのようなもの)を使いました。
美しいスープ。その名前の由来はずっとわからずにいます。
いざスクレイピング

今回はこちらのブログを参考にしました。
[サルでもできる]という一文が最高に心強かったです。
しかもこのブログの執筆者はデータの整形もされていたので参考にさせて頂きました。
それでは他力本願でたどりついた競馬レース情報のうちの一つをご紹介しましょう。
[['テリオスルイ', 'ジオフロント', 'モンテディオ', 'マテンロウベントス', 'レイワミノル', 'シゲルシャイン', 'ボスコ', 'アルメイダミノル', 'メイショウイナホ', 'タガノカイ', 'ウルピカ', 'ヴェールアップ'], ['菱田裕二', '武豊', '岩田望来', '川田将雅', '幸英明', '国分恭介', '吉田隼人', '藤岡康太', '浜中俊', '藤岡佑介', '古川吉洋', '松山弘平'], [7, 2, 6, 10, 4, 9, 1, 8, 3, 5, 11, 12], [123.6, 124.1, 124.3, 124.4, 124.4, 124.5, 125.1, 125.8, 126.3, 126.4, 126.7, 128.2], [28.7, 4.1, 8.2, 7.4, 11.4, 119.6, 6.4, 49.4, 3.4, 34.8, 182.2, 18.2], [0.5833333333333334, 0.3125, 0.375, 0.5833333333333334, 1.0, 0.6041666666666666, 0.8333333333333334, 0.3333333333333333, 0.125, 0.3125, 0.7916666666666666, 0.125], [458, 460, 478, 464, 470, 450, 488, 506, 492, 516, 506, 462], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1], [2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2], [54.0, 54.0, 53.0, 54.0, 54.0, 54.0, 54.0, 54.0, 54.0, 54.0, 54.0, 54.0], [35.7, 36.2, 36.2, 36.3, 35.7, 36.1, 36.7, 37.9, 38.6, 38.2, 38.2, 40.2], [8, 2, 5, 4, 6, 11, 3, 10, 1, 9, 12, 7], '2歳新馬', 1013, 6, 3, 0, 2000, 1, 0, 1, 2870, [700, 170, 230], 6690, [1840, 3450, 630], 15430, 12470, 111960]
0:馬名
1:騎手
2:馬番
3:走破時間
4:オッズ
5:通過
6:体重
7:体重变化
8:性(0:牡,1:牝,2:セ)
9:年齡
10:斤量
11:上がり
12:人気
13:レース名
14:日付
15:競馬場
16:クラス
17:芝、ダート
18:距離
19:回り
20:馬場狀態
21:天気
22:单勝
23:複勝
24:馬連
25:ワイド
26:馬単
27:三連複
28:三連単

情報が多い!!!!!
今回スクレイピングしたデータは2018~2022年の中央競馬、10362レースです。
量も多い!!!
参考にしたブログではとても高度な解析をしていましたが、今回は初心者ということでもっとシンプルな機械学習を行いたいと思います。
今回使用した機械学習について
最も実装しやすい機械学習を調べたところ、scikit-learn(サイキット・ラーン)というものが良いということになりました。
scikit-learnもPythonのライブラリが用意されており、比較的扱いやすいアルゴリズムであるというところが魅力です。
scikit-learnも道具箱のようなイメージです。
その中に様々なアルゴリズムがあり、今回はランダムフォレストというものを採用しました。
ランダムフォレストについて
物事を判定するのに、決定木というものがしばし使われます。
このような決定木をいろんな種類、たくさん作ってやろうぜというのがランダムフォレストのざっくりとした説明です。
木がたくさんでフォレストになったわけですね。
機械学習を学ぶ上で最初に触れるアルゴリズムの一つだと聞いたので初心者の私はこちらを採用しました。
ランダムフォレストを実装してみる
先ほどスクレイピングして得られたデータのリスト1つずつにレース1つの情報がすべて入っています。
そのままでは少し扱いにくいので、今回は初心者なりに簡単なやり方を模索していきます。
思いついたのはレース単位のリストではなく、馬単位のリストを作成するということです。
約1万レースのデータの上では14万頭以上の馬が走っているので、今回は14万の要素を持つリストにレース情報を分割しました。
まずは説明変数を作ってみる
説明変数とは機械学習で判定するために必要な情報で、今回で言えばその馬が3位に入るかどうかに影響する要因、例えばオッズ、馬体重、その日の天気などのことです。
data_dataというリストを作成し、その中に入れてみましょう。
#説明変数を作成
import numpy as np
db = np.delete(data, [0,1,3,5,10,11,12,13,14,22,23,24,25,26,27,28], 1) #dataはレース情報が入ったリスト
k = 0
data_data = [[0 for j in range(13)] for i in range(len(data_target))]
for i in range(len(data)):
for j in range(len(db[i][0])):
data_data[k] = [db[i][0][j],db[i][1][j],db[i][2][j],db[i][3][j],db[i][4][j],db[i][5][j],db[i][6],db[i][7],db[i][8],db[i][9],db[i][10],db[i][11],db[i][12]]
k += 1
print(data_data[100])ソースコードが汚いという苦情はすべて受け入れます。
しかし初心者という免罪符を大きく振らせてください。
2行目ではNumpyを使って今回の機械学習ではいらないと判断した列を削除しています。
ここでは各レースの払い戻し金額や走破タイムなんかはいらないと判断しました。
5行目でdata_dataのゼロ行列を作成し、それぞれの馬情報をその下で代入しているといった感じです。
最終的に作成したdata_dataのひとつの行はこのようになりました。
[8, 6.6, 506, 0, 2, 3, 5, 4, 1, 1800, 0, 0, 0]
0:馬名
1:オッズ
2:体重
3:体重变化
4:性(0:牡,1:牝,2:セ)
5:年齡
6:競馬場
7:クラス
8:芝、ダート
9:距離
10:回り
11:馬場狀態
12:天気
競馬場や天気など情報をフラグに置き換えて表現したものもあります。
この要素が14万以上ある状態です。
目的変数を作る
目的変数とはその決定木が最終的に判定したいことであり、ここではその馬が3位に入るかどうかです。
もともとダウンロードしてきたデータの馬情報は着順に並んでいましたのでここは簡単に作れました。
#目的変数を作成
data_target = []
for i in range(len(data)):
for ii in range(3):
data_target.append(1)
for j in range(len(data[i][0])-3):
data_target.append(0)data_targetの中身はこんな感じです。
[1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
その馬が3着に入った時には1のフラグを立てました。
いざランダムフォレストへ
ランダムフォレスト自体の実装はお手本通りにやるだけだったので意外と簡単でした。
from sklearn import ensemble
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X = data_data
y = data_target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
clf = ensemble.RandomForestClassifier(n_estimators=1000, random_state=1)
clf.fit(X_train, y_train) #学習を実行
y_pred = clf.predict(X_test) #評価テストを実行
accuracy_score(y_test,y_pred) #正解率を表示出力結果は、
0.8094732713471611でした。まさかの80%超え、意外と正解率良いの!?
今回のテストを混合行列に表しました。
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, y_pred, labels=[1, 0]))| 予想:3着以内 | 予想:4着以下 | |
| 実際:3着以内 | 3025 | 6251 |
| 実際:4着以下 | 2007 | 32060 |
ここでは赤字で書いたところが正解を表します。
でもこうやってみたら、ほとんど4着以下って予想していますね。
3着以内と予想しても、その馬がくる確率は3/5じゃないですか!

うーん、なんとも言えない感じになっちゃったのか、、、?
いざ、決戦へ!
さて本日、デイリー杯2歳ステークスというレースがありました。
daily_2sai = [
[1,7.0,490,8,0,2,8,9,0,1600,1,0,0],
[2,3.0,538,6,0,2,8,9,0,1600,1,0,0],
[3,16.3,468,-2,0,2,8,9,0,1600,1,0,0],
[4,22.7,432,4,0,2,8,9,0,1600,1,0,0],
[5,98.9,444,-2,0,2,8,9,0,1600,1,0,0],
[6,6.6,456,2,0,2,8,9,0,1600,1,0,0],
[7,15.5,474,-6,0,2,8,9,0,1600,1,0,0],
[8,4.7,468,2,0,2,8,9,0,1600,1,0,0],
[9,74.6,488,18,0,2,8,9,0,1600,1,0,0],
[10,5.7,482,4,0,2,8,9,0,1600,1,0,0]
]
y_pred = clf.predict(daily_2sai)
print(y_pred)[1 1 0 0 0 0 0 0 0 0]
どうやら1、2の馬が来るらしいです。
2の馬は1番人気ですが、1の馬は4番人気。
AIが選んだ馬をワイド(2頭選んで、3着以内にその2頭が両方来たらあたり)で買います。

結果は、、、
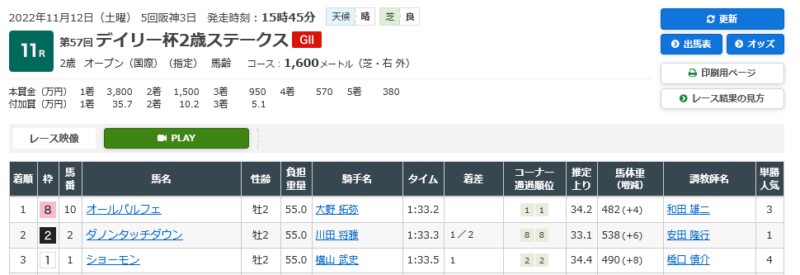
すごいじゃん!!!!!!!当たってるじゃん!!!!!

ワイドで100円が400円になりました。
これで今晩は大量のもやしが買えそうです。
おわりに
いかがだったでしょうか。
機械学習の実装部分は非常に簡単なものを採用したため、今後はその馬の前走のデータやタイムなんかも入れながら的中率を上げていきたいと思います。
それでは、また。







