こんにちは、りょうです。身近な交差点で事交通故が多いなっていう交差点ありますよね。
今回はPythonを使用して、Pandasの勉強がてら全国の事故が起こりやすい交差点を絞り込んでいこうと思います。
Python勉強したての方も一緒にマスターしていきましょう!
扱うオープンデータについて
情報が細かい、数値がわからない
今回扱う元データは、警視庁のホームページにある交通事故統計原票です。
下記のサイトからダウンロードできます。

2つあるCSVファイルには合計約70万件の交通事故の情報があり、事故の日時や場所だけでなく、天気や標識の有無、事故に関する詳細な情報が数値で表されています。
以下がその例です。
1,10,059,0001,2,000,001,40010,1,0000,234,2020,01,06,07,20,11,2,3,3,14,00,7,00,23,00,23,04,9,20,70,1,4,21,45,65,03,04,31,31,01,01,04,04,42,13,3,3,2,1,2,2,2,4,425637403,1413108483,2,3
1,10,059,0002,2,000,001,40010,1,0000,213,2020,01,16,06,39,23,1,3,1,14,00,7,00,23,00,23,04,9,01,70,1,4,21,65,45,03,13,31,01,01,11,10,10,80,16,2,2,2,2,2,2,4,2,424247129,1413908484,5,3コード表を見つけてくるのも、一つ一つ見比べていくのも大変そう。今回扱うのはとりあえず日時、緯度経度くらいにしておこうかなと。
それにしても、緯度経度の表記方法がわからない。あれって小数点がついているものじゃないの?
緯度と経度って2種類表記方法があるんですか?
試しに本票から緯度経度を一つ取り出してみます。
「425637403,1413108483」
うーん見たことない表記…。と思い、検索してみるとこれは緯度経度を度分秒で表しているらしいです。
なじみのある度表記にするために以下のサイトを参考にしてソースコードを持ってきました。
def dms2deg(dms):
h = dms[0]
m = dms[1]
s = dms[2]
deg = Decimal(str(int(h) + (int(m) / 60) + (float(s) / 3600))).quantize(Decimal('0.0001'), rounding=ROUND_HALF_UP)
return degとりあえず必要な情報を抽出
緯度経度の表記を直しながら必要な情報を抽出するソースコードを載せておきます。
from decimal import Decimal, ROUND_HALF_UP
import csv
from datetime import datetime as dt
def dms2deg(dms):
h = dms[0]
m = dms[1]
s = dms[2]
deg = Decimal(str(int(h) + (int(m) / 60) + (float(s) / 3600))).quantize(Decimal('0.0001'), rounding=ROUND_HALF_UP)
return deg
with open("honhyo_2020.csv", mode="r") as f1:
with open("honhyo_2020_after.csv", mode="a") as f2:
rows = csv.reader(f1)
header = next(rows) //1行目はラベル情報だったので読み飛ばす
writer = csv.writer(f2)
for row in rows:
tstr = row[11]+'-'+row[12]+'-'+row[13]+' '+row[14]+':'+row[15]+':00' //ばらばらだった日時情報を一つのdatetime型に
tdatetime = dt.strptime(tstr, '%Y-%m-%d %H:%M:%S')
lat = row[54]
lat = dms2deg((lat[0:2], lat[2:4], lat[4:6] + "." + lat[6:]))
lon = row[55]
lon = dms2deg((lon[0:3], lon[3:5], lon[5:7] + "." + lon[7:]))
writer.writerow([tdatetime, lat, lon])
print('OK')上記のコードは”honhyo_2020.csv”を読み取ってまとめた結果を”honhyo_2020_after.csv”に出力しています。
これにより生成されたCSVファイルは以下のようです。
2018-12-28 10:10:00,43.2369,141.8297
2019-01-06 13:25:00,42.9517,141.5111右から日時、緯度、経度の順番で書いている。これが事故の件数、約70万行にわたります。
わりとすっきりしたのではなかろうか。
各交差点の事故の起きた回数を調べる
事故回数を数えて、交差点の被りを消していく
先ほど生成したCSVファイルは約70万件の事故の記録をまとめたものである。そのため次は緯度経度が同じ件は同一の交差点で起きた事故とみなし、被っている交差点を一つにまとめながらその事故回数をカウントしていきます。
最終的には事故多発とみなした交差点だけを記録します。
import pandas as pd
df = pd.read_csv("honhyo_2020_after.csv", encoding="shift-jis",names=['date', 'lat', 'lon']) //先ほどのファイルを読み込む
df['dup'] = df.groupby(['lat', 'lon']).transform('count') //それぞれの交差点が何回出てくるか数えて新しい列に'dup'として記録
df1 = df[~df.duplicated(subset=['lat','lon'])] //かぶっている交差点を削除
df2 = df1[df1['dup']>2]
df2.to_csv('busy_intersection.csv') //CSVファイルに記録
print('OK')8行目では交差点の登場回数’dup’が3以上の要素をピックアップしています。つまり、2年間で3回以上交通事故が起きている交差点を危ない交差点だとみなして記録しました。
これにより生成されたCSVファイルは以下のようです。
100,2019-01-02 11:50:00,43.0649,141.3196,3
149,2019-01-14 17:10:00,43.0972,141.3842,3右からid、日時(各交差点につき1つ)、緯度、経度、事故発生回数の形式です。
ちなみに7247か所の交差点の情報になり、扱いやすいデータになったといえます。
おわりに
意外と簡単にできた
いかがだったでしょうか。僕としては良いPandasの復習となったので有意義な時間でした。
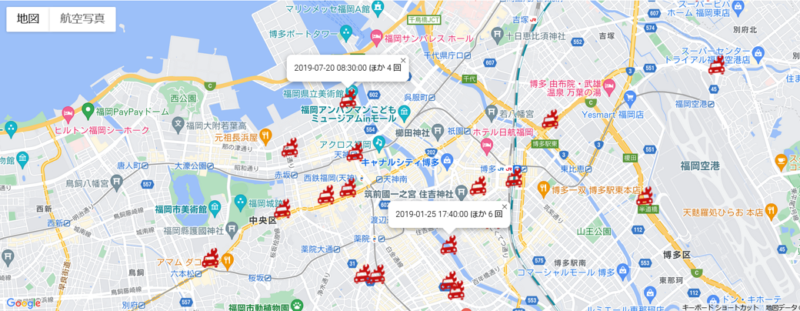
ちなみに今回取得した交差点情報をGoogleマップ上に表示してみたので、機会があればまた記事にしたいと思います。それでは、お疲れさまでした!