

みなさん、競馬って楽しいですよね!その迫力ある馬たちの走りや、レースの結果を予測する楽しさは、他のものでは味わえません。でも、正直言って、穴馬の予測って難しい…。あれだけ研究して、結果は「うーん、これはなかったな」ということ、私も何度か経験しました。
そんな中、最近のテクノロジー界隈で話題になっているのが「機械学習を使った競馬予測」。ちょっと難しそうな名前ですが、要はコンピュータを使って、データから馬の勝敗を予測する方法です。今回の記事では、その中でも特に「前走データ」を活用した新しい予測方法をご紹介します。
オッズって便利だけど、時々誤解を生むことも…。だから、この新しい方法ではオッズを使わず、馬の実力だけで予測してみました。果たしてどうなるのか、一緒に見ていきましょう!
競馬予測の新しい風:前走データの重要性
競馬の予測って、誰もが一度は挑戦したことがあると思います。新聞の予想欄を見たり、専門家のコメントを参考にしたり…。でも、正直、どれもこれも当たらないと感じたこと、ありませんか?私もそうでした。でも、実は競馬の結果にはヒントが隠されているんです!
そのヒントとは「前走データ」。馬が前回どう走ったか、という情報ですね。これまでの伝統的な予測方法では、この前走データはあまり注目されてこなかったのですが、最近ではその重要性が見直されています。なぜなら、前走の結果は、馬の現在のコンディションや、次のレースでのポテンシャルを示す大切な指標となるからです。
この前走データを主役にした新しい予測方法、実はかなりの注目を浴びているんですよ!今回、その魅力と効果について、一緒に探っていきましょう!
機械学習と前走データ:完璧な組み合わせ
前回の記事で作成したデータセット(db2)を用いてモデルを作成していきます

ちなみにデータセットにはこのような情報が入っています。
- 馬番
- 体重
- 体重変化
- 性 (0:牡, 1:牝, 2:セ)
- 年齢
- 距離
- 馬場状態
- 前走順位(仮置き)
- 前走距離(仮置き)
- 前々走順位(仮置き)
- 前々走距離(仮置き)
- 前々々走順位(仮置き)
- 前々々走距離(仮置き)
今回作成したコードを解説していきます。
from sklearn import ensemble
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
#目的変数を作成
data_target = []
for i in range(len(data)):
for ii in range(3):
data_target.append(1)
for j in range(len(data[i][0])-3):
data_target.append(0)
X = db2
y = data_target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
clf = ensemble.RandomForestClassifier(n_estimators=1000, random_state=1)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy_score(y_test,y_pred)結果は以下のようになりました。
0.7881565425103464
オッズありで検証した時(0.8くらいだった)よりも正解率が落ちているだと、、、!

今回もテストを混合行列に表しました。
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, y_pred, labels=[1, 0]))| 予想:3着以内 | 予想:4着以下 | |
| 実際:3着以内 | 1313 | 6447 |
| 実際:4着以下 | 1180 | 27063 |
来ると言った2493頭のうち実際に来たのは1313頭。予想の的中率は50%といったところでしょうか。
しかし、今回はオッズ情報を省いているため、世の中の人気に引っ張られない機械学習独自の視点から予想を展開してくれることでしょう。
実践!レースのテスト結果
さて、ここまで色々と新しい予測方法についてお話ししてきましたが、みなさんも「実際にどうなの?」と思っていることでしょう。そこで、早速、実際のレースでこの新しいモデルを試してみました!
選んだのは「浦和 3日目ほおずき特別(C1)」。
このレースで、従来のモデルは1番人気のトーセンプリシラを1着と予想。一方、今回ご紹介している新しいモデルは、2番人気のステラセイコーを1着と予想しました。
新モデル(オッズなし・前走あり):
4:ステラセイコー
旧モデル(オッズあり):
1:トーセンプリシラ
レースの結果、、、
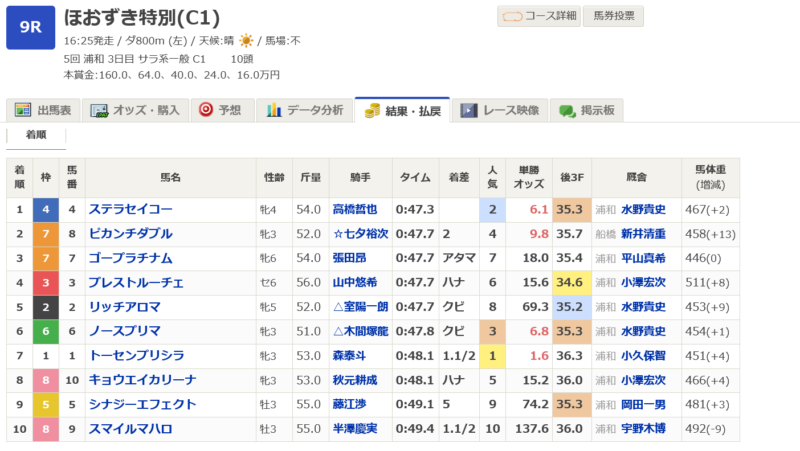
ステラセイコーが見事1着に!これは、新しいモデルの予測力の高さを示す結果と言えるでしょう。
まぁ、1レースの結果だけで完全に判断するのは難しいですが、新しいアプローチがもたらす変化を感じていただけたのではないでしょうか?これからも、さらなるデータやレース結果をもとに、予測モデルをブラッシュアップしていきたいと思います!
このモデルのメリット・デメリット
新しいものには、いつも良い点と悪い点がありますよね。この新しい競馬予測モデルも例外ではありません。さっそく、このモデルの良いところ、もう少し改善が必要なところを見ていきましょう!
メリット
- 前走データの活用:これまであまり注目していなかった前走データを活用することで、馬の近況や実力をより正確に捉えることができます。
- オッズ情報を排除:オッズに左右されず、真の実力だけで予測を行うため、穴馬の発見も期待できます。それにより、当たった際の配当金が高額になることが期待できます。
デメリット
- まだ実績が少ない:新しいモデルなので、実際のレースでの予測実績がまだ少ないです。時間とともに、さらなる検証が必要です。
- 的中率が高くない:予想の正答率という点ではオッズを加味したモデルに劣ります。しかし、旧モデルでは予想が的中しても人気馬であることが多いため配当金が少なくなりかねません。
まとめと今後の展望
このモデルの一番の特徴、それは「前走データ」をメインにした点。そして、オッズ情報を使わないという大胆な挑戦。この2つの組み合わせにより、これまでの予測の枠を超えた新しい予測の可能性を感じてもらえたら嬉しいです。
しかし予想は完璧なものではないので、機械学習の予想と、自分が来ると思った馬を組み合わせながら競馬を楽しんでほしいです。
競馬の予測は、結果が全て。でも、その過程も楽しんでいただけたらと思います。新しい予測モデルで、次のレースがさらに楽しみになるような結果をお届けできるよう、これからも頑張ります!






